
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- Motion generation
- Diffusion
- 텐서
- CVPR 2023
- image synthesis
- 이미지 생성
- 튜토리얼
- DataSet
- T2M-GPT
- DataLoader
- 파이토치
- VQ-Diffusion
- pytorch
- image generation
- Human Motion
- HumanML3D
- Today
- Total
고도를 기다리며
[논문] Vector Quantized Diffusion Model for Text-to-Image Synthesis (CVPR2022) 본문
[논문] Vector Quantized Diffusion Model for Text-to-Image Synthesis (CVPR2022)
MING.G 2023. 7. 28. 16:00본 글은 Vector Quantized Diffusion Model for Text-to-Image Synthesis를 읽고 이해한 내용을 정리하기 위해 적은 글입니다.
혹, 잘못된 부분이나 수정해야할 부분이 있다면 언제든 댓글로 남겨주세요.
Abatract
본 논문에서는 text-to-image 생성을 위한 vector quantized diffusion (VQ-Diffusion) model을 제안한다. 제안하는 방법은 DDPM의 조건부 variant로 잠재공간이 모델링된 vector qunatized variational autoencoder (VQ-VAE)를 기반으로 한다. 저자들은 latent-space method가 기존 기법에 존재하는 unidirectional bias를 제거하고, accumulation of error를 피하기 위한 mask-and-replace diffusion 전략을 취함으로써 latent-space method가 text-to-image 분야에 적합하다고 주장한다.
제안하는 기법의 실험결과는 VQ-Diffusion이 비슷한 수의 parameter를 가지는 전통적인 autoregressive(AR)모델과 비교했을 때, 더 좋은 text-to-image 생성 결과를 보인다. 이전의 GAN-based test-to-image 모델과 비교했을 때, VQ-Diffusion은 더 복잡한 장면을 다룰 수 있고, 생성된 이미지의 품질을 크게 향상시켰다.
마지막으로, 본 논문의 저자는 제안하는 기법에서 사용되는 이미지 생성을 위한 계산량이 reparameterization을 통해 매우 효율적으로 만들어질 수 있다고 말한다. 전통적인 AR 모델에서는 text-to-image 생성 시간은 출력 이미지의 해상도에 비례하여 선형적으로 증가하게된다. 따라서 일반적인 크기의 이미지를 생성하는데에도 꽤 많은 시간이 소요된다.
VQ-Diffusion은 quatlity와 speed사이에서 더 좋은 균형을 이룰 수 있다. 본 논문의 실험은 reparameterization된 VQ-Diffusion 모델이 더 좋은 이미지 quality를 보이면서도, 전통적인 AR 모델보다 15배 더 빠르다는 것을 보여준다.
Introduction
최근 neural language processing(NLP)에서 Transformer의 성공은 컴퓨터 비전 문제에 성공적인 언어 모델을 사용하는데 큰 관심을 불러일으켰다. AR model은 text-to-text 생성(즉, 기계번역)에서 text-to-image 으로의 전환에서 가장 자연스럽고 인기있는 접근 방식 중 하나다. AR model에 기반하여, 최근에 DALL-E는 text-to-image 분야에서 괄목할만한 성능을 보여주었다.
이러한 성공에도 불구하고, text-to-image 생성 기법에는 여전히 향상되어야 할 약점이 존재한다.
- unidirectional bias
- 기존 기법은 pixel 혹은 token을 예측할 때, reading order(좌측 상단 -> 우측 하단)로 예측함
- 모든 prefix 픽셀 또는 토큰과 text description에 attention을 둠
- 이런 고정된 order를 사용하는 경우, 중요한 문맥적인 정보가 이미지의 어떤 부분에서든 나올 수 있기 때문에, 이미지 생성 시 unnatural한 bias를 생성하게 됨
- accumulated prediction errors
- inference에서의 각 step은 이전에 샘플링된 token에 기반하여 수행됨
- 하지만 이전에 샘플링된 token은 training stage에서 교사강요 기법으로 입력되는 것과는 다름
- inference에서 한번 예측된 token은 수정될 수 없기 때문에, 에러가 그 이후의 token에 전달됨
본 논문에서는 vector quantized diffusion (VQ-Diffusion) 모델을 제안한다. 이때, VQ-Diffusion 모델은 unidirectional bias를 제거하고, accumulated prediction error를 피할 수 있다.
VQ-Diffusion 모델은 먼저, vector quantized variational autoencoder(VQ-VAE)로 시작해서, 조건부 Denoising Diffusion Probabilistic Model(DDPM)을 이용하여 latent space를 학습한다. 논문에서는 이렇게 학습된 latent space가 text-to-image 생성 분야에 적합하다고 말하고 있다. 간단히 말하자면, VQ-Diffusion 모델은 데이터 분포를 forward diffusion process를 역으로 수행하여 샘플링한다. 이때, forward process는 입력과 같은 차원의 점점 더 많은 noisy latent variable을 생성하고, 결국 고정된 timestep 이후에는 완전한 noise를 생성하게 된다. 이러한 noise 결과로부터 reverse process는 조건부 전이 분포를 학습하여 점진적으로 원하는 데이터 분포를 향해 latent variable을 denoise한다.
그렇다면 본 논문에서 제안하는 VQ-Diffusion은 어떻게 unidirectional bias와 accumulated prediction error 문제를 해결한 것일까?
- unidirectional bias
- VQ-Diffusion은 독립된 text encoder와 diffusion image decoder로 구성되어 있음
- inference step의 시작에, 모든 이미지 token은 masked 되어있거나, random으로 설정되어 있음
- denoising diffusion process는 입력 text에 기반하여 점진적으로 image token의 확률 분포를 추정함
- 각 step에서 diffusion image decoder는 이전 단계에서 예측된 전체 이미지의 모든 token들의 문맥 정보를 활용하여 새로운 확률 밀도 분포를 추정하고, 이 분포를 사용하여 현재 단계에서의 토큰들을 예측함
- 이 bidirectional attention은 각 token의 예측과 unidirectional bias를 제공하기위한 global한 문맥을 제공함
- accumulation prediction error
- mask and replace 전략이 accumulation of error를 예방함
- 학습 단계에서, 교사 강요 전략을 사용하지 않는 대신, 마스크된 token과 random token을 모두 사용하여 네트워크로 하여금 마스크된 token을 예측하고, 잘못된 token을 수정하도록 함
- inference 단계에서는, 각 단계에서 모든 token의 밀도 분포를 업데이트 함으로써, 모든 token의 새로운 분포에 따라 다시 샘플링 함
- 따라서 이러한 기법이 잘못된 token을 수정하고 error accumulation을 예방함
- 기존의 replace-only diffusion 전략과 비교하면, uncoditional 이미지 생성에 있어서 마스크된 token은 효과적으로 네트워크의 attention을 마스크된 영역으로 이끌어내므로, network에 의해 조사되어야 하는 token의 조합의 수를 획기적으로 줄일 수 있음. 따라서 이 mask-and-replace 기법은 네트워크의 수렴을 가속화함
Background: Learning Discrete Latent Space of Images Via VQ-VAE
Transformer 구조는 뛰어난 표현력으로 image 생성에서 좋은 가능성을 보여주고 있다. 따라서 본 연구에서 저자들은 transforer로 하여금 text to image의 맵핑을 학습하는것을 목표로 한다. sequence의 길이의 제곱으로 계산량이 증가하기 때문에, raw pixel을 직접 사용하는 transformer는 계산적으로 어려움이 있다. 이러한 문제를 해결하기 위해, 최근의 연구들은 image sequence length를 줄이고, image를 이산적인 image token을 이용하여 나타내는 방법을 제안한다. 이후로, 이 감소된 문맥 길이에서 transformer는 효과적으로 학습될 수 있고, text to image token의 번역을 배울 수 있다.
정식으로 말하면, vector quantized variational autoencoder(VQ-VAE)가 사용되는데, model은 encoder $E$와 decoder $G$, codebook $Z = \{z_k \}_{k=1}^K \in \mathbb{R}^{K \times d}$를 포함한다. 이때, codebook은 유한개의 embedding vector를 포함하고, $K$는 codebook의 크기이며, $d$는 각 코드의 차원이다.
input image $x \in \mathbb{R}^{H \times W \times 3}$ 가 주어졌을 때, encoder를 통해 image token의 공간(spatial) 집합 $z_q$를 얻을 수 있다. ($ z = E(x) \in \mathbb{R}^{h \times w \times d}$) 그리고 spatial-wise Quantizer $Q(\cdot)$은 각각의 공간집합 $z_{ij}$를 가장 가까운 codebook의 원소 $z_k$로 맵핑한다.
$z_q = Q(z) = \left ( \arg \min_{z_k \in Z} || z_{ij} - z_k||_2^2 \right ) \in \mathbb{R}^{h \times w \times d}$
이때, $h \times w$는 encoding된 sequence의 길이를 나타내고, 보통 $H \times W$보다 훨씬 작다. 이후 이미지는 decoder를 통해 재구성된다. (즉, $ \tilde{x} = G(z_q)$다.) 따라서 이미지 생성은 latent distribution으로부터 image token을 샘플링하는것과 동일하다고 할 수 있다. 이때, image token은 양자화된 잠재변수로, 이산값을 가진다.
encoder $E$와 decoder $D$, 그리고 codebook $Z$는 아래 loss 함수로 end-to-end로 훈련될 수 있다.
$\mathcal{L}_{VQVAE} = ||x - \tilde{x}||_1 + ||sg[E(x)] - z_q||^2_2 + \beta||sg[z_q] - E(x)||^2_2$
이때, $sg[\cdot]$는 stop-gradient 연산을 나타낸다. 실제로, 논문에서는 위의 Loss 함수의 두 번째 term을 exponential moving average(EMA)로 치환하여 codebook을 업데이트한다. 이 방법은 더 loss 함수를 직접 사용하는 것보다 더 효과적이다.
Vector Quantized Diffusion Model
text-image 쌍이 주어지면, 사전 학습된 VQ-VAE를 이용하여 이산 image token $x \in \mathbb{Z}^N$을 얻는다. 이때 $N = hw$이며, token의 sequence length를 의미한다. VQ-VAE의 codebook의 크기가 $K$라고하면, $i$번째의 image token $x^i$는 codebook의 특정 원소의 index를 가진다. (즉, $x_i \in \{ 1, 2, ..., K \}$) 반면, text token $y \in \mathbb{Z}^M$은 BPE-encoding을 통해 얻어진다. 전반적인 text-to-image framework은 조건부 전이 분포 $q(x|y)$를 최대화하는 것으로 볼 수 있다.
이전의 autoregressive model (DALL-E, CogView)은 text token과 이전에 예측한 image token에 의존하여 각 image token을 순차적으로 예측한다. ($q(x|y) = \prod ^N _{i=1} q(x^i|x^1, \dots, x^{i-1}, y)$)
autoregressive model은 text-to-image 생성에서 괄목할만한 성능을 보여주었지만, 몇가지 제한사항이 있다. 먼저, image token은 단방향 순서로 예측되기 때문에 2차원 데이터 구조를 무시하고 이미지 모델링의 표현을 제한한다. 다음으로, training의 경우 ground truth를 사용하고 inference는 이전의 token으로부터 예측하기 때문에, train-test 사이의 차이가 존재한다. 교사강요 또는 exposure bias는 이전 샘플링의 실수로 인해 오차를 누적시킨다. 더욱이 각 token을 예측하기 위해 네트워크의 순전파를 요구하므로 낮은 해상도의 잠재공간에서도 많은 시간이 소요된다. 따라서 AR 모델은 실 사용에는 적합하지 않다.
저자들은 VQ-VAE 잠재공간을 non-autoregressive한 방법으로 모델링하는 것을 목표로 한다. 제안하는 VQ-Diffusion 방법은 diffusion model을 이용하여$q(x|y)$를 최대화하는 방법이다. 최근 연구는 대부분 연속적인 diffusion model에 초점을 맞추고 있지만, 범주형 분포에 대한 연구는 적다. 본 논문에서 저자들은 conditional variant discrete diffusion process를 text-to-image생성에 적용한다.
1) Discrete diffusion process
높은 수준에서, forward diffusion process는 고정된 Markov chain $q(x_t|x_{t-1})$ 점차적으로 이미지 데이터 $x_0$을 손상시킨다. 즉, $x_{t-1}$의 몇 token을 랜덤으로 replace하면, 고정된 timestep $T$ 이후에는, forward process는 $z_0$과 동일한 차원의 점점 더 noisy한 잠재변수 $z_1, ..., z_T$를 생산한다. 이때 $z_T$는 pure한 noise token이 된다.
noise $z_T$에서 시작하여 reverse process는 점진적으로 잠재 변수를 denoising하고, reverse 분포인 $q(x_{t-1}|x_t, x_0)$에서 순차적으로 샘플링하여 실제 데이터 $x_0$을 복원한다. 하지만 $x_0$은 inference stage에서는 알려지지 않았기 때문에, 저자는 transformer network가 전체 데이터 분포에 따른 conditional transit distribution인 $p_\theta(x_{t-1}|x_t, y)$를 근사할 수 있도록 학습시킨다. 조금 더 자세히 살펴보자면, single image token $x_0^i$는 $x_0$의 $i$번째 token으로, codebook의 요소를 나타낸다. (즉, $x_0^i \in \{ 1, 2, ..., K \}$다.)
(이후 수식에서는 혼란을 줄이기 위해 superscripts $i$를 표시하지 않는다.)
본 논문에서는 $x_{t-1}$에서 $t$로의 전이확률을 $[Q_t]_{mn}$ 행렬을 사용한다. 이때 행렬은 $[Q_t]_{mn} = q(x_t=m|x_{t-1}=n) \in \mathbb{R}^{K \times K}$로 나타낼 수 있다. 다음으로 모든 token sequence에 대한 forward Markov diffusion process를 이 행렬을 이용해 다시 적어보면 아래와 같이 나타낼 수 있다.
$q(x_t|x_{t-1}) = v^\top(x_t)Q_t v(x_{t-1})$
이때, $v(x)$는 one-hot column vector로, 길이는 token의 길이이며, $x$의 입력만 1로 표현된다. 따라서, $x_t$의 범주형 분포는 $Q_t v(x_{t-1})$로 나타낼 수 있다.
Markov chain의 특성으로 인해, 중간 단계를 marginalize하여 $x_0$으로부터 임의의 시간 단계인 $x_t$의 확률을 직접 유도할 수 있다.
$q(x_t|x_0) = v^\top (x_t) \bar{Q}_t v(x_0), with \ \bar{Q}_t = Q_t, \dots Q_1.$
반면, 또다른 주목할만한 특징은 $z_0$에 condition을 더함으로써, 이 diffusion process의 사후분포를 다룰수 있다는 것이다.
$q(x_{t-1}|x_t, x_0) = {{q(x_t|x_{t-1}, x_0) q(x_{t-1}|x_0)} \over {q(x_t|x_0)}} = {{\left (v^\top(x_t)Q_tv(x_{t-1}) \right) \left ( v^\top(x_{t-1})\bar{Q}_{t-1}v(x_0) \right )} \over {v^\top(x_t) \bar{Q}_tv(x_0)}}$
전이행렬 $Q_t$는 이산 diffusion model에서 매우 중요하고 신호를 noise로부터 역으로 복원하는게 어렵지 않도록 주의해서 설계되어야 한다. 이전의 연구들은 작은 uniform noise를 적용한 categorical distribution과 전이행렬을 소개하고 있다.
$ \begin{equation*}
Q_{t} =
\begin{bmatrix}
{\alpha_t + \beta_t} & {\beta_t} & \cdots & {\beta_t} \\
{\beta_t} & {\alpha_t + \beta_t} & \cdots & a_{2,n} \\
\vdots & \vdots & \ddots & \vdots \\
{\beta_t} & {\beta_t} & \cdots & {\alpha_t + \beta_t}
\end{bmatrix}
\end{equation*} $
이때, $\alpha_t \in [0, 1]$ 이고 $\beta_t = (1-\alpha_t)/K$다. (이는 전이행렬의 각 행의 합은 1이 되어야 하므로 당연하다.) 각 token은 현재 상태로 남기 위해 $(\alpha_t + \beta_t)$의 확률을 가지고 있으며, 모든 $K$ 카테고리로 다시 샘플되기 위한 $K\beta_t$의 확률을 가지고 있다.
그럼에도 불구하고 uniform diffusion을 사용하여 데이터를 손상시키는 것은 약간 공격적인 방법이라고 할 수 있다. 먼저, 순서가 있는 데이터를 위한 Gaussian diffusion process와 다르게, image token은 완전히 상관없는 category로 대체될 수 있다. 또한 이로인해 token의 의미적인 변화가 급격하게 발생하게 된다. 다음으로 network는 사전에 대체된 token을 밝혀내고 이를 고치기 위해 추가적인 노력을 들여야 한다. 사실, 지역적인 문맥에서 의미의 충돌로 인해 다른 image token에 대한 역 추정은 경쟁을 형성하고, 신뢰할 수 있는 token을 식별하는데 딜레마에 빠질 수 있다.
Mask-and-replace diffusion strategy
uniform diffusion에 대한 위의 문제를 해결하기 위해, 저자들은 mask language model에서 영감을 얻어 몇몇 token을 확률적으로 마스킹하여 손상시키는 방식을 제안한다. 제안하는 방식을 사용하면, 손상된 위치가 역추정 네트워크에 명시적으로 알려질 수 있다. 특히, 저자들은 [MASK] token이라는 추가적인 특별한 token을 소개한다. 따라서 각 token은 이제 $(K+1)$ 개의 이산적인 상태를 가지게 된다.
저자들은 mask diffusion을 아래와 같이 정의한다. 각각의 원본 token은 [MASK] token으로 대체될 확률 $\gamma_t$와 uniform하게 diffuse될 확률(즉 , 다른 category로 변환될 확률) $K\beta_t$와 현재 상태로 남아있을 확률 $\alpha_t = 1-K\beta_t + \gamma_t$를 가지게 된다. [MASK] token은 항상 자신의 상태를 유지한다. 따라서 전이행렬은 아래와 같이 다시 정의된다.
$\begin{equation*}
Q_{t} =
\begin{pmatrix}
{\alpha_t + \beta_t} & {\beta_t} & \cdots & {0} \\
{\beta_t} & {\alpha_t + \beta_t} & \cdots & {0} \\
\vdots & \vdots & \ddots & \vdots \\
{\gamma_t} & {\gamma_t} & \cdots &{1}
\end{pmatrix}
\end{equation*}$
이때, $Q_t \in \mathbb{R}^{(K+1) \times (K+1)}$ 이다.
이 mask-and-replace 전이의 장점은 아래와 같다.
- 손상된 token을 구분할 수 있고, 이는 역 추정과정을 용이하게 한다.
- mask만 사용하는 방법과 비교하여, 저자들은 token masking 외에도 아주 작은 양의 uniform noise를 포함하는것이 필요하다는 것을 증명했다. 그렇지 않으면 $x_t \neq x_0$ 일때 무의미한 사후확률을 얻게된다.
- random하게 token을 바꾸는 것은 네으워크로 하여금 문맥에 집중하도록 한다.
- 누적 전이 확률 $\bar{Q}_t$와 확률 $q(x_t|x_0)$는 closed form으로 계산될 수 있다.
$\bar{Q}_tv(x_0) = \bar{\alpha}_tv(x_0) + (\bar{\gamma}_t - \bar{\beta}_t)v(K+1) + \bar{\beta}_t$
이때, $\bar{\alpha}_t = \prod_{i=1}^t \alpha_i$, $\bar{\gamma}_t = 1-\prod_{i=1}^t(1-\gamma_i)$, 그리고 마지막으로 $\beta_t = (1 - \bar{\alpha}_t - \bar{\gamma}_t) /K$는 사전에 계산되어 저장될 수 있다. 따라서 $q(x_t|x_0)$의 계산량은 $O(tK^2)$에서 $O(K)$로 감소한다.
2) Learning the reverse process
diffusion process를 reverse하기 위해, 저자들은 denoising network $p_\theta(x_{t-1}|x_t, y)$가 사후 전이 분포 $q(x_{t-1}|x_t, x_0)$를 추정하도록 학습시킨다. network는 Variational Lower Bound(LVB)를 최소화하도록 훈련된다.
$\mathcal{L}_{vlb} = \mathcal{L}_0+\mathcal{L}_1+\dots+\mathcal{L}_{T-1}+\mathcal{L}_T$
$\mathcal{L}_0 = -logp_\theta(x_0|x_1,y)$
$\mathcal{L}_{t-1} = D_{KL}(q(x_{t-1}|x_t, x_0) || p_\theta(x_{t-1}|x_t, y)) $
$\mathcal{L}_T = D_{KL}(q(x_T|x_0) || p(x_T))$
$p(x_T)$는 timestep $T$에서의 사전 분포다. 제안된 mask-and-replace diffusion에서 prior는 다음과 같이 정의될 수 있다.
$p(x_T) = [\bar{\beta}_T, \bar{\beta}_T, \dots , \bar{\beta}_T, \bar{\gamma}_T,]^\top$
전이행렬 $Q_t$는 training 동안 고정된다. 따라서 $\mathcal{L}_T$는 상수이므로 training동안 무시된다.
Reparameterization trick on discrete stage
network parameterization 생성 품질에 크게 영향을 준다. posterior $q(x_{t-1}|x_t, x_0)$을 직접적으로 예측하는 대신, 최근의 연구들은 surrogate variable에 근사하는 방법을 사용하고 있다. discrete setting에서, 저자들은 network로 하여금 noiseless token 분포인 $p_\theta(\tilde{x}_0|x_t, y)$를 각 reverse step마다 예측하도록 한다. 따라서, 이를 이용하여 reverse 전이 분포를 계산하면 다음과 같다.
$p_\theta(x_{t-1}|x_t, y) = \Sigma^K_{\tilde{x}_0=1} q(x_{t-1}|x_t, \tilde{x}_0) p_\theta(\tilde{x}_0|x_t, y) $
(내가 이해한 바로는 결국 DDIM과 같아지는 것 같다..)
reparameterization trick에 따라, 본 논문에서는 보조로 denosing 목적 함수를 도입한다. 이 목적함수는 네트워크가 noise없는 토큰 $x_0$을 예측하도록 한다.
$\mathcal{L}_{x_0} = -log_{p_\theta}(x_0|x_t, y)$
저자들은 이 loss를 $\mathcal{L}_{vlb}$에 적용했을 때, 이미지 퀄리티가 더욱 증가하는 것을 발견했다.
Model architecture
저자들은 $p_\theta(\tilde{x}_0|x_t, y)$ 분포를 예측하기 위해 encoder-decoder transformer를 제안한다.

제안하는 framework는 text encoder와 diffusion image decoder 2개의 부분으로 이루어져있다.
먼저, text encoder는 text tokens $y$를 입력으로 받아 조건부 특징 sequence를 생성한다. diffusion image decoder는 image token $x_t$과 timestep $t$를 입력으로 받아 noiseless한 token 분포 $p_\theta(\tilde{x}_0|x_t, y)$를 생성한다. decoder는 몇개의 transformer block과 softmax layer를 포함하고 있다. 각 transformer block은 full attention과 text information과 결합하기 위한 cross attention, feed forward block을 포함하고 있다. 현재의 timestep $t$는 network로 주입되고, 이때 Adaptive Layer Normalization(AdaLN) 연산을 수행한다.
$AdaLN(h, t) = a_t \ LayerNorm(h) \ + \ b_t$
이때, $h$는 intermediate 활성화 값이며, $a_t$와 $b_t$는 timestep embedding을 선형 변환한 결과다.
Fast inference strategy
inference stage에서는 reparameterization trick을 이용해, 확산 모델에서 일부 단계를 건너뛰어 빠른 inference를 달성할 수 있다. 즉, time stride를 $\Delta_t$로 가정하고 sampling image 단계를 $x_T, x_{T-1}, x_{T-2}, ... , x_0$으로 설정하는 대신, $x_T, x_T- \Delta_t, x_T-{2\Delta_t}, ..., x_0$로 설정했다. 이 결과, 생성된 이미지의 quality는 조금 낮아졌지만, sampling을 훨씬 효율적으로 할 수 있었다.
Experiments
Datasets.
본 논문에서는 text-to-image 생성 방법 평가를 위해 CUB-200, Oxford-102, MSCOCO 데이터셋을 사용했다. 또한 제안하는 방법의 scalability를 증명하기 위해 LAION-400M, CC3M, CC12M또한 사용했다.
Training Details
제안하는 방법의 VQ-VAE의 encoder와 decoder는 VQGAN을 따라 셋팅되었다. VQGAN은 GAN loss를 사용하여 더욱 실감있는 이미지의 생성이 가능하다. 본 논문에서 저자는 Open Image dataset에서 학습된 공개적으로 사용이 가능한 VQGAN을 적용했다. 이 모델은 256X256 크기의 이미지를 32X32개의 token으로 변환하고 codebook의 크기인 $K$는 2886으로 설정했다.(사용하지 않는 코드는 제거함) 또한, text encoder로는 CLIP을 사용했다. 이 2개의 encoder는 모두 training동안 freeze했다.
기존 text-to-image 모델과의 공정한 비교를 위해 파라미터의 수를 유사하게 설정해야 할 필요가 있었고, 이를 위해 저자들은 2개의 다른 diffusion image decoder setting을 사용했다.
- VQ-Diffusion-S(Small)
- 18개의 transformer block (192 dimension)
- model parameter 개수: 34M
- VQ-Diffusion-B(Base)
- 19개의 transformer block (1024 dimension)
- model parameter 개수: 370M
- VQ-Diffusion-F(Fine tune)
- base model을 더 큰 dataset을 이용하여 학습하고 fine-tuninig하여 사용
기본 실험 setting은 다음과 같다.
- timestep $T$ : 100
- loss weight $\lambda$ : 0.0005
- transition matrix $\bar{\gamma}_t$, $\bar{\beta}_t$ : 0~0.9 까지 0.1씩 증가
- AdamW : $\beta_1$ = 0.9, $\beta_2$ = 0.96
- learning rate : set to 0.00045 after 5000 iteration of warmup
1) Comparison with state-of-the-art methods
본 논문에서는 성능 비교를 위해 GAN-based method와 DALL-E, CogView와의 비교를 수행한다.
비교를 위해서 생성된 30k 이미지와 30k의 real image간의 FID를 계산한다.

결과에서 제안하는 모델 중 작은 모델인 VQ-Diffusion-S가 CUB-200과 Oxford-102 데이터 셋에서 좋은 성능을 보이는 것으로 나타났다. 또한 base model인 VQ-Diffusion-B는 더 좋은 성능을 보여주었고, VQ-Diffusion-F는 가장 좋은 성능을 달성했다.
2) In the wild text-to-image synthesis

본 논문에서는 in-the-wild image 생성능력을 보여주기 위해 LAION-400M 데이터셋에서부터 cartoon, icon, human을 subset으로 하여 학습을 진행했다. (여기서 in-the-wild image란, uncontrolled된, 즉 실내에 특정 환경에서 촬영된 사진이 아닌 사진을 이야기하는 듯 하다.) 그 결과, DALL-E나 CogView보다 훨씬 더 적은 수의 parameter를 사용하면서도 좋은 성능을 보이고 있다.
AR(autoregressive) model과 비교하면, 제안하는 방식은 top-left to down-right순서로 이미지를 생성하는 것이 아니라, 전체를 고려하여 생성하기때문에 다양한 vision task에 적용될 수 있다. irregular mask inpainting 등과 같은 다른 task에 적용될 때에는 새로운 모델을 다시 training할 필요가 없다. 그 이유는 저자들이 [MASK] token을 제안하고 있기 때문이다. 이 [MASK] token은 unconditional mask inpainting이나 text conditional mask inpainting과 같은 task를 해결하는데 사용될 수 있다.
3) Ablations
Number of timesteps.
저자들은 CUB-200 데이터셋에서 training과 inference 단계에서의 timestep에 대한 실험을 진행했다. 이를 통해 저자들은 training step이 10에서 100으로 증가할때, 결과가 향상되었지만 200까지 증가할때에는 수렴하는것을 발견했다. 그래서 저자들은 timestep의 기본 설정을 100으로 하여 실험을 진행했다.
또한, 빠른 inference 전략을 위해 저자들은 10, 25, 50, 100 inference step에서의 생성된 이미지를 평가했는데, 3/4 inference step을 사용하지 않아도 좋은 성능을 보이는 것을 발견했다.

Mask-and-replace diffusion strategy.
저자들은 제안하는 Mask-and-replace 전략이 성능에 어떤 이점을 주는지 보여주기 위해 Oxford-102 데이터에서 실험을 진행했다. 저자들은 final mask rate($\bar{\gamma}_T$)를 다르게 설정하여 성능을 보였다. 이때 $\bar{\gamma}_T$를 1로 설정하면 mask only가 되며, $\bar{\gamma}_T$를 0으로 설정하면 replace only가 된다.
실험 결과, $M = 0.9$일 때 가장 좋은 성능을 보였다. 만약 $M > 0.9$가 되면, error accumulation problem이 발생하고 $M < 0.9$인 경우에는 network가 어떤 부분에 더 많은 attention을 해야하는지 찾는데 어려움이 있다.
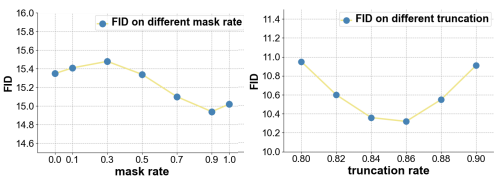
Truncation.
저자들은 truncation sampling 전략이 제안하는 discrete diffusion based model에서 매우 중요하다고 주장한다. 이는 low probability token에서 sampling하는 것을 방지해준다. 특히, 저자들은 $p_\theta(\tilde{x}_0|x_t, y)$에서 top $r$개의 token만을 inference 단계에서 유지한다. 이를 실험으로 통해 보여주기 위해 저자들은 CUB-200데이터셋에서 다른 truncation rate $r$을 이용한 실험을 진행했다. 그 결과 가장 좋은 성능은 truncation rate가 0.86일때였다.
VQ-Diffusion vs VQ-AR.
공정한 비교를 위하여 저자들은 diffusion image decoder를 autoregressive decoder와 비교했다. 다른 모든 설정을 동일하게 하고, CUB-200 데이터셋을 이용하여 성능을 비교한 결과 S, B 모델에서 VQ-Diffusion 모델이 큰 차이로 VQ-AR 모델을 앞섰다.

4) Unified generation model
제안하는 모델은 general하여 다른 image synthesis task에 적용될 수 있다.
먼저, Conditional Image synthesis의 경우, 주어진 class label에 맞는 이미지를 생성하기 위해 저자들은 text encoder network와 cross attention part를 제거했다. 그리고 class label을 AdaLN operator에 입력했다.
이때, 모델은 24개의 transformer block으로 이루어져 있고 dimension은 512다. 또한 모델은 ImageNet 데이터셋을 이용하여 학습되었고, VQ-VAE는 앞서서 차용한 VQ-GAN 형태를 차용하였다. 이때, image는 256X256에서 16X16으로 downsampling된다.
Unconditional image synthesis의 경우, 저자들은 모델을 FFHQ256 데이터셋을 이용하여 학습되었고, 동일하게 16x16으로 downsampling 되었다.

비록, 성능은 BigGAN보다 낮지만, 제안하는 방법이 다양한 image synthesis task에도 적용될 수 있음을 보여준다.
'공부한것 > 대학원' 카테고리의 다른 글
| [오류] CHOIS 논문 코드 실행 오류 해결 (0) | 2026.01.28 |
|---|---|
| [논문] T2M-GPT: Generating Human Motion from Textual Descriptions with Discrete Representations (0) | 2023.07.10 |
| [Dataset] HumanML3D 다운로드 (2) | 2023.06.30 |
